 1domagoj1
uto 24.12.2019 00:54
1domagoj1
uto 24.12.2019 00:54
Programiranje
[Tutorial] Uvod u umjetnu inteligenciju, UNM
1domagoj1
uto 24.12.2019 00:54
1domagoj1
uto 24.12.2019 01:26
Vratimo se na trenutak gornjoj jednadžbi korekcije težina. Ta jednadžba još se zove i perceptronovo pravilo učenja. U ovoj formuli w_i(k) predstavlja i-tu težinu u k-tom koraku, a w_i(k+1) tu istu težinu u sljedećem koraku, u k+1-om koraku. Eta (η) je konstanta koja predstavlja faktor ili stopu učenja, t (skraćeno od engl. target) predstavlja stvarnu klasu primjera, o predstavlja predviđenu klasu primjera, a x_i je i-ta vrijednost primjera x. Da bismo malo bolje shvatili kako ova jednadžba funkcionira idemo ugrubo proći kroz jedan primjer.
Pretpostavimo da imamo dva ulaza u neuron. Sjetimo se, treći ulaz je zadani, uvijek je iznosa 1, nikad se ne navodi posebno već se podrazumijeva, a naziva se pomakom ili pristranošću (engl. bias). Neka su x1 = 0.5, x2 = 1 (x0 znamo da je uvijek jednak 1 po definiciji), a sve početne težine neka budu w0 = w1 = w2 = 0.5. Izračunajmo ukupnu pobudu neurona:
net = x0*w0 + x1*w1 + x2*w2 = 1*0.5 + 0.5*0.5 + 1*0.5 = 1.25
Pogledajmo sada definiciju funkcije praga i pogledajmo je li 1.25 iznosom veće od 0? Pa svakako vrijedi da je 1.25 > 0, što znači da će izlaz iz našeg neurona biti f(1.25) = 1. Drugim riječima, naš neuron je okinuo - aktivan je. Sada nam slijedi korekcija težina. Za korekciju težina pretpostavimo da je stvarna klasa ovog našeg primjera x = (x0 x1 x2) = (1 0.5 1) bila 0 jer se prema gornjem pravilu učenja korekcija vrši kad je primjer klasificiran neispravno, a naš neuron je predvidio 1. Korekcija težina obavlja se prema gornjem izrazu za korekciju težina (pretpostavimo da nam je stopa učenja eta = 0.1):
w0(1) = w0(0) + eta * (t - o) * x0 = 0.5 + 0.1 * (0 - 1) * 1 = 0.4
w1(1) = w1(0) + eta * (t - o) * x1 = 0.5 + 0.1 * (0 - 1) * 0.5 = 0.45
w2(1) = w2(0) + eta * (t - o) * x2 = 0.5 + 0.1 * (0 - 1) * 1 = 0.4
Iz ovog računa vidimo da je sljedeći iznos težine w0 jednak zbroju prethodnog iznosa w0 i ovog umnoška koji smo već objasnili. Analogno izračunamo i ostale težine i dobili smo nove težine koje iznose w0 = 0.4, w1 = 0.45, w2 = 0.4. Sad bi dalje nastavili učiti perceptron na način da mu damo sljedeći primjer x = (x0 x1 x2), pa sljedeći i tako u krug dok sve primjere ne klasificira točno što ujedno znači i da više neće biti korekcije težina jer se korekcija vrši samo ukoliko je primjer netočno klasificiran. To se vidi i iz jednadžbe, ukoliko su t i o jednakog iznosa taj čitavi umnožak bit će 0, a nešto + 0 = nešto.
Ono što je bitno ovdje napomenuti je da je ovako definirani neuron zapravo linearni klasifikator, a to znači da je granica na temelju koje odlučuje kojoj klasi pripada neki primjer linearna, tj. u 2D prostoru to je pravac, u 3D prostoru to je ravnina, a u višedimenzionalnom prostoru to je hiperravnina (a to si ne možemo niti zamisliti). Drugim riječima, da bi učenje perceptrona konvergiralo, tj. da dođe do toga da više nema promjena u korekciji težina (jer je u tom slučaju svaki primjer u skupu podataka ispravno klasificiran) taj skup podataka mora biti linearno odvojiv. Da bi bilo jasnije o čemu govorim, pogledajmo sljedeću sliku:
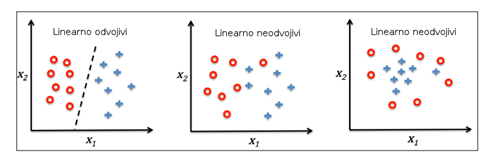 Iz ove slike vidimo da je samo prvi skup podataka linearno odvojiv i jedino je za njega moguće naći pravac koji će razdijeliti dostupne podatke u dvije klase. Drugi je skup podataka gotovo linearno odvojiv, ali je svejedno nemoguće pronaći pravac koji će razdijeliti podatke u dvije klase - uvijek par njih "bježi". Treći skup podataka pogotovo nije linearno odvojiv i tek tu nepostoji apsolutno nikakav pravac koji bi mogao razdijeliti te primjere u dvije klase. Očigledno je da bi učenje perceptrona konvergiralo i da bi mogli reći da je model naučen, skup podataka na kojem ga učimo mora biti linearno odvojiv što se u stvarnom svijetu, pogađate, (gotovo) nikad ne događa. Ukoliko skup podataka nije linearno odvojiv, perceptron će beskonačno osvježavati težine i zapravo nikad neće pronaći pravac (ili ravninu/hiperravninu) koji bi odvajao dvije klase. Zbog toga je perceptron ustvari prilično glup model, ali dovoljno je dobar za (ovakva) teoretska razmatranja.
Iz ove slike vidimo da je samo prvi skup podataka linearno odvojiv i jedino je za njega moguće naći pravac koji će razdijeliti dostupne podatke u dvije klase. Drugi je skup podataka gotovo linearno odvojiv, ali je svejedno nemoguće pronaći pravac koji će razdijeliti podatke u dvije klase - uvijek par njih "bježi". Treći skup podataka pogotovo nije linearno odvojiv i tek tu nepostoji apsolutno nikakav pravac koji bi mogao razdijeliti te primjere u dvije klase. Očigledno je da bi učenje perceptrona konvergiralo i da bi mogli reći da je model naučen, skup podataka na kojem ga učimo mora biti linearno odvojiv što se u stvarnom svijetu, pogađate, (gotovo) nikad ne događa. Ukoliko skup podataka nije linearno odvojiv, perceptron će beskonačno osvježavati težine i zapravo nikad neće pronaći pravac (ili ravninu/hiperravninu) koji bi odvajao dvije klase. Zbog toga je perceptron ustvari prilično glup model, ali dovoljno je dobar za (ovakva) teoretska razmatranja.
Sada smo pokrili svu potrebnu teoriju. Prije nego nastavimo pisati konkretnu implementaciju modela, idemo pripremiti podatke s kojima ćemo raditi. Sam kod modela će biti puno jasniji ako znamo točno kako nam izgledaju podaci s kojima ćemo raditi, tj. kakvog su oblika.
Za edukacijske svrhe često se koristi skup podataka Iris koji je 1936. godine u jednom svom radu sastavio britanski statističar i biolog Ronald Fisher za objašnjenje postupka zvanog linearna diskriminativna analiza (kojeg nećemo obrađivati). Riječ je o skupu podataka u kojem se nalazi po 50 uzoraka svake od tri vrste perunike (Iris setosa, Iris virginica i Iris versicolor). U skupu se nalaze četiri izmjerene značajke: duljina i širina čašice cvijeta i duljina i širina latica u centimetrima. Na temelju kombinacija tih četiriju značajki Fisher je razvio linearni diskriminativni model kojim je mogao razlikovati jednu vrstu perunike od druge. Danas se taj njegov skup podataka koristi kao tipičan test za razne klasifikacijske metode u strojnom učenju (poput npr. stroja potpornih vektora) pa ćemo ga koristiti i mi za naš model perceptrona.
Za baratanje podacima koristit ćemo biblioteku pandas. Biblioteka pandas nam omogućava lako korištenje struktura podataka i alata za podatkovnu analizu u Pythonu. Prvo što moramo učiniti je uvesti biblioteku i dobaviti skup podataka na svoje računalo:
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.tail()
0 1 2 3 4
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
Ove dvije linije koda su prilično jasne. Pozovemo pandasovu metodu read_csv() koja će danu putanju pročitati i obraditi kao datoteku CSV, s tim da ju argumentom header=None upućujemo da zaglavlja u podacima nema pa će metoda dodati zaglavlje u obliku numeriranih stupaca (u suprotnom će za zaglavlje uzeti prvi redak što nam ne paše). Sada se podaci nalaze u posebnoj pandasovoj strukturi podataka DataFrame, a to znači da možemo koristiti sve blagodati pandasovih metoda za manipulaciju podacima. Sljedeća linija je metoda tail() koja očigledno pokazuje zadnjih 5 unosa u pandasovom podatkovnom okviru. Da bismo podatke mogli koristiti u svom modelu perceptrona, moramo ih još malo obraditi.
Sjetimo se da u skupu podataka imamo tri vrste perunika s po 50 primjeraka svake vrste što znači da ukupno imamo 150 primjeraka (što se vidi iz rednog broja u izlazu metode tail() - 149, indeksiranje kreće od nule). Ako ste probali otvoriti poveznicu iz argumenta metode read_csv() u pretraživaču (može se, riječ je o običnoj tekstualnoj datoteci) mogli ste primjetiti da su "igrom slučaja" (naravno da nije igrom slučaja, namjerno je tako složeno) primjerci poredani i grupirani upravo po vrstama. Tu činjenicu možemo iskoristiti kod naše dodatne obrade podataka. Naime, nama trebaju samo dvije vrste perunika jer ćemo raditi binarnu klasifikaciju (imat ćemo samo dvije klase). S obzirom da po vrsti ima 50 primjeraka to znači da su prvih 100 primjera u skupu podataka točno dvije vrste. Stoga ćemo odabrati prvih 100 primjera (0:100), samo zadnji stupac (4 - a to su latinska imena perunika) te izvući sirove vrijednosti iz pandasovog podatkovnog okvira (.values) u posebnu varijablu:
y = df.iloc[0:100, 4].values
Ako sada ispišemo y, dobit ćemo ovako nešto:
array(['Iris-setosa', 'Iris-setosa', 'Iris-setosa', ... , 'Iris-versicolor', 'Iris-versicolor'], dtype=object)
Trenutno u polju imamo 50 "Iris-setosi" i 50 "Iris-versicolora", međutim, mi ne možemo baš nešto raditi sa znakovnim nizovima stoga ćemo ove dvije vrste perunika pretvoriti u dvije klase (cijele brojeve): 0 i 1:
y = np.where(y == 'Iris-setosa', 0, 1)
NumPyeva metoda where() jednostavno gleda gdje u polju imamo ispunjen uvjet "y == 'Iris-setosa'" i tamo postavlja 0, a na sva ostala mjesta 1. Kako imamo samo dvije vrste perunika u polju, efektivno smo svakoj odredili njenu klasu - "Iris-setosa" je 0, a "Iris-versicolor" je 1.
Sad kad imamo svoje klase, potrebno je još odrediti i same primjere koji tim klasama pripadaju:
X = df.iloc[0:100, [0, 2]].values
Ništa strašno, opet smo uzeli prvih 100 primjera (0:100), međutim ovaj put smo uzeli prvi i treći stupac ([0, 2] - koji predstavljaju duljinu čašice cvijeta i duljinu latice). Ako sada ispišemo X, trebali bi dobiti ovako nešto:
array([[ 5.1, 1.4],
[ 4.9, 1.4],
[ 4.7, 1.3],
...
[ 5.7, 4.1]])
Ovdje imamo matricu 100 x 2 koja predstavlja naše primjere sa značajkama. Ova matrica naziva se ulazni prostor ili prostor primjera. Također imamo i matricu, tj. vektor s oznakama klasa (varijabla y). Zajedno to dvoje tvori nešto što zovemo skup primjera za učenje, a koji se može tablično prikazati ovako:
 Zašto smo uzeli samo dvije značajke, duljinu čašice cvijeta i duljinu latica? Odgovor je jednostavan, zato da bi primjere mogli prikazati u dvodimenzionalnom prostoru gdje je jedna os duljina čašice, a druga os duljina latica. Kad smo objašnjavali da je kod linearnog klasifikatora granica u 2D prostoru pravac, u 3D prostoru ravnina, a u višedimenzionalnom prostoru hiperravnina, nismo spomenuli što zapravo taj prostor (i koji to prostor uopće) čini n-dimenzionalnim. Upravo broj značajki neki prostor čini n-dimenzionalnim, a prostor o kojem govorimo je ranije navedeni ulazni prostor, tj. prostor primjera. Svaka dodatna značajka dodaje jednu dimenziju tom prostoru. Kako je već i 3D prostor nespretno prikazati, a više od toga i nemoguće, uzeli smo upravo dvije značajke zbog jednostavnosti ilustracije. Ukoliko sada iscrtamo naše X-eve i svakome dodijelimo njegovu oznaku y, tj. klasu dobit ćemo nešto ovako:
Zašto smo uzeli samo dvije značajke, duljinu čašice cvijeta i duljinu latica? Odgovor je jednostavan, zato da bi primjere mogli prikazati u dvodimenzionalnom prostoru gdje je jedna os duljina čašice, a druga os duljina latica. Kad smo objašnjavali da je kod linearnog klasifikatora granica u 2D prostoru pravac, u 3D prostoru ravnina, a u višedimenzionalnom prostoru hiperravnina, nismo spomenuli što zapravo taj prostor (i koji to prostor uopće) čini n-dimenzionalnim. Upravo broj značajki neki prostor čini n-dimenzionalnim, a prostor o kojem govorimo je ranije navedeni ulazni prostor, tj. prostor primjera. Svaka dodatna značajka dodaje jednu dimenziju tom prostoru. Kako je već i 3D prostor nespretno prikazati, a više od toga i nemoguće, uzeli smo upravo dvije značajke zbog jednostavnosti ilustracije. Ukoliko sada iscrtamo naše X-eve i svakome dodijelimo njegovu oznaku y, tj. klasu dobit ćemo nešto ovako:
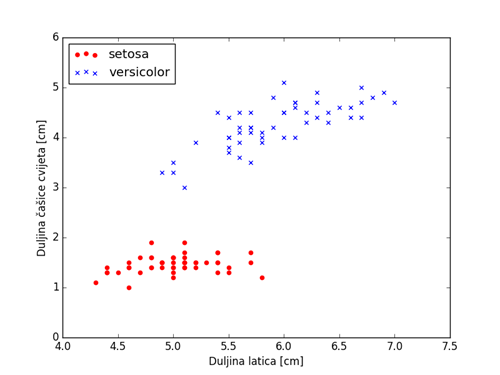 Uz ovo objašnjenje i ovu sliku trebalo bi biti sve puno jasnije: što to zapravo radimo kad kažemo da klasificiramo primjere, što je to granica koja će u ovom slučaju biti pravac (iz slike je vidljivo da je takav pravac moguć, a pažljiviji će primjetiti da zapravo ima beskonačno mnogo pravaca koji bi mogli razdijeliti ove dvije klase), što je to ulazni prostor ili prostor primjera, što su to značajke te kako utječu na veličinu ulaznog prostora. Klase smo označili različitim bojama i oblicima. Svaki primjer može se prikazati kao vektor u ulaznom prostoru (vektor ide iz ishodišta, a vrh mu je u točki), ali zbog jednostavnosti crtanja prikazujemo samo točke. Čitavi kod koji smo do sada napisali za obradu podataka i za njihovo iscrtavanje je ovaj:
Uz ovo objašnjenje i ovu sliku trebalo bi biti sve puno jasnije: što to zapravo radimo kad kažemo da klasificiramo primjere, što je to granica koja će u ovom slučaju biti pravac (iz slike je vidljivo da je takav pravac moguć, a pažljiviji će primjetiti da zapravo ima beskonačno mnogo pravaca koji bi mogli razdijeliti ove dvije klase), što je to ulazni prostor ili prostor primjera, što su to značajke te kako utječu na veličinu ulaznog prostora. Klase smo označili različitim bojama i oblicima. Svaki primjer može se prikazati kao vektor u ulaznom prostoru (vektor ide iz ishodišta, a vrh mu je u točki), ali zbog jednostavnosti crtanja prikazujemo samo točke. Čitavi kod koji smo do sada napisali za obradu podataka i za njihovo iscrtavanje je ovaj:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# dohvat i priprema podataka
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', 0, 1)
X = df.iloc[0:100, [0, 2]].values
# iscrtavanje na grafu
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('Duljina latica [cm]')
plt.ylabel('Duljina čašice cvijeta [cm]')
plt.legend(loc='upper left')
plt.savefig('iscrtani_primjerci.png')
# plt.show() # ako se želi prikazati u prozoru
Sada kada smo pokrili osnovnu teoriju i pripremili podatke za naš budući model, možemo krenuti na samu implementaciju modela.
Krenimo s očitim, uvezimo biblioteku NumPy i definirajmo novu klasu zvanu Perceptron:
import numpy as np
class Perceptron(object):
def __init__(self, eta=0.01, epochs=10):
self.eta = eta
self.epochs = epochs
Ovime smo definirali novu klasu Perceptron i napisali njezin konstruktor koji kao argumente prima stopu učenja eta i broj epoha učenja. Jedna epoha definira se kao jedan prolazak kroz sve primjere za učenje u skupu podataka. Zadane vrijednosti (ukoliko konstruktoru ne predamo neke svoje) su 0.01 i 10. Stopu učenja i broj epoha spremamo u varijable self.eta i self.epochs. U Pythonu ključna riječ self znači isto što i u Javi ili C++-u ključna riječ this, međutim, u Pythonu se mora eksplicitno navoditi ("eksplicitno je bolje od implicitnog" - pitonska mudrost) dok se u C++-u/Javi, a i drugim C-olikim jezicima implicitno podrazumijeva.
Prisjetimo se, od čega se sastoji umjetni neuron. Sastoji se od ulaza, težina, "tijela" u kojem se računa net te prijenosne funkcije f koja daje izlaz. Prvo trebamo izračunati net (sad je dobro vrijeme da ponovite množenje matrica/vektora, ukoliko ne znate ili ste zaboravili):
def _net(self, X):
return np.dot(X, self.weights[1:]) + self.weights[0]
Ovdje smo upotrijebili NumPyevu metodu dot() koja obavlja matrično množenje, u ovom slučaju između matrice X i vektora self.weights[1:]. Matrica X je dimenzija N x 2 (N je neki općenit broj - u našem slučaju je 100), no self.weights je dimenzija 3 x 1 i stoga smo X množili sa self.weights[1:] (bez nulte težine - [1:] znači da odabiremo sve elemente od indeksa 1 do kraja, drugim riječima, indeks 0 smo izostavili) koji je dimenzija 2 x 1, a nultu težinu self.weights[0] smo naknadno zbrojili. Ovo možemo tako napraviti zato što ulaz x0 uz težinu w0 iznosi konstantnih 1, a 1 * w0 = w0. S obzirom da je povratna vrijednost metode dot() vektor, a self.weights[0] je skalar, NumPy interno radi tzv. širenje gdje od tog skalara stvara vektor istih vrijednosti takvih dimenzija da zbrajanje bude moguće - u ovom slučaju N x 1.
Kao rezultat smo dobili vektor dimenzija N x 1 koji predstavlja net za svaki od N primjera. Drugim riječima, izračunali smo net = w0*x0 + w1*x1 + w2*x2 za N primjera odjednom, u jednoj liniji koda bez ikakvih petlji. Ako se sjećate, ranije sam spomenuo da se preferira vektorski zapis, a ovo je jedan od razloga zašto. Sav teret proračuna prebacili smo na veoma optimiranu biblioteku NumPy koja je specijalno namijenjena upravo ovakvim proračunima. Ovu liniju koda je bitno shvatiti, ukoliko vam nije jasna, preporučam na komadu papira napisati matricu 5 x 2 i vektor 2 x 1 te ručno obaviti množenje (možete s brojevima ili bez, kako vam je lakše) da vidite kako će izgledati rezultat (rezultantni vektor mora biti dimenzija 5 x 1). Isti je postupak i u kodu s matricom N x 2, razlika je jedino u veličini.
Sad kad imamo net, tj. netove, možemo napisati metodu za predviđanje kojoj klasi primjer pripada. Ovo je vrlo jednostavna metoda, jedna linija koda. Prisjetimo se definicije: ako je ukupna pobuda <i>net<i> negativna ili jednaka nuli, neuron ne okida, tj. na izlazu daje 0, a ako je pobuda pozitivna neuron će okinuti, tj. na izlazu će dati 1:
def predict(self, X):
return np.where(self._net(X) > 0.0, 1, 0)
S metodom where() već smo se susreli. Unutar metode where() zovemo ranije definiranu metodu self._net() koja će vratiti netove. Netovi koji su pozitivni (> 0.0) dobit će oznaku 1, a svi ostali oznaku 0. Ova bi linija koda trebala biti jasna sama po sebi.
Napišimo sada metodu za provedbu učenja. Ukoliko ste ikada radili s bibliotekom sklearn ili tek budete, oni u svojim implementacijama modela metodu za učenje nazivaju fit pa ćemo i mi slijediti tu konvenciju:
def fit(self, X, y):
self.weights = np.zeros(1 + X.shape[1])
self.errors = []
Za početak, definirali smo varijablu self.weights koja će sadržavati sve težine koje ulaze u naš neuron. Za to smo uzeli drugu dimenziju matrice X i dodali joj 1. Sjetimo se, matrica X je dimenzija N x 2, što znači da X.shape[1] iznosi 2. Na ove dvije težine dodali smo još jednu koja odgovara težini w0 kod koje x0 uvijek iznosi fiksnih 1. Dakle, ukupno imamo tri težine: w0, w1 i w2. Definirali smo i varijablu self.errors koja nam predstavlja broj krivo klasificiranih primjera kako bi kasnije mogli iscrtati iznose tih grešaka. Zanimljivost kod Pythona je to što smo u ovom slučaju podatkovne članove klase (atribute klase) definirali u metodi fit() (Python ih je dinamički stvorio), a ne u konstruktoru, tj. u metodi __init__() kako se to obično mora napraviti u C-olikim jezicima.
Sada nam trebaju dvije petlje, jedna vanjska koja će prolaziti po epohama te jedna unutarnja koja će prolaziti po primjerima. Još samo preostaje perceptronovo pravilo učenja, tj. onu jednadžbu prenijeti u kod:
for _ in range(self.epochs):
misclassifications = 0
for x, t in zip(X, y):
correction = self.eta * (t - self.predict(x))
self.weights[1:] += correction * x
self.weights[0] += correction # može pisati i correction * 1
misclassifications += int(correction != 0.0)
self.errors.append(misclassifications)
Analizirajmo pobliže unutarnju petlju. Ona se može napisati i vektorski, međutim ovako je sam proces učenja jednostavnije objasniti i shvatiti. Prolazimo po svakom primjeru x te uz njega uzimamo i pripadnu klasu y (kao varijablu t). Prvo što radimo je računamo ispravak koji je potrebno dodati težinama kako bi ih se popravilo. Nakon toga ispravljamo te težine i to sve po već ranije navedenoj formuli perceptronovog pravila učenja. Težini w0, tj. pristranosti samo dodajemo korekciju jer ako se prisjetimo od ranije, kod pristranosti vrijednost x0 je 1, a umnožak bilo čega s 1 je opet ta ista vrijednost. Zatim računamo pogrešku. Pogreška nam je u ovom slučaju broj krivo klasificiranih primjera. Naime, ako su varijabla t i predviđena vrijednost jednake, varijabla correction bit će 0. Ako su različite, varijabla correction bit će 1 i u tom slučaju pridodajemo jednu pogrešnu klasifikaciju varijabli misclassifications. Sama pogreška, tj. broj krivo klasificiranih primjera nema nikakvog utjecaja na algoritam učenja perceptrona i služi nam samo kao informacija i zanimljivost.
Sada imamo sve potrebne elementa za izgradnju perceptrona. Čitava klasa perceptrona izgleda ovako:
class Perceptron(object):
def __init__(self, eta=0.01, epochs=10):
self.eta = eta
self.epochs = epochs
def fit(self, X, y):
self.weights = np.zeros(1 + X.shape[1])
self.errors = []
for _ in range(self.epochs):
misclassifications = 0
for x, t in zip(X, y):
correction = self.eta * (t - self.predict(x))
self.weights[1:] += correction * x
self.weights[0] += correction
misclassifications += int(correction != 0.0)
self.errors.append(misclassifications)
return self.errors
def predict(self, X):
return np.where(self._net(X) > 0.0, 1, 0)
def _net(self, X):
# ovo je "privatna" metoda što podvlaka _ prije naziva i naznačava
return np.dot(X, self.weights[1:]) + self.weights[0]
Svoj perceptron možemo pokrenuti i naučiti na sljedeći način:
p = Perceptron()
p.fit(X, y)
gdje je X matrica svih primjera, a y su pripadne klase.
Predvidjeti u koju klasu spada neki novi primjer možemo pozivanjem metode predict() kojoj predamo taj novi primjer:
prediction = p.predict([3.5, 4])
print(prediction)
Naučimo onda naš perceptron na našim podacimo o perunikama:
# dohvat i priprema podataka
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', 0, 1)
X = df.iloc[0:100, [0, 2]].values
p = Perceptron()
errors = p.fit(X, y)
Zadana vrijednost broja epoha je 10 (postavljena u konstruktoru), stoga će se naš perceptron učiti 10 epoha. Ako se sjetimo teorije o perceptronu, rekli smo da se postupak učenja zaustavlja kad su svi primjeri klasificirani ispravno. No mi smo ovdje implementirali perceptron tako da odradi određeni broj epoha i onda se zaustavlja. Razlog tome je što se kod neuronskih mreža uobičajeno i radi na taj način - postavi se određeni broj epoha za vrijeme kojih se mreža uči. Perceptron je model koji odskače od takve prakse - njegov algoritam učenja zaustavlja se kad su svi primjeri točno klasificirani. To je moguće, kao što smo već ranije rekli, samo ako su svi primjeri linearno odvojivi. U stvarnom svijetu to nije slučaj - podaci su gotovo uvijek linearno neodvojivi. Ovaj kod je trivijalno preinačiti da se postupak učenja zaustavlja kad su svi primjeri točno klasificirani i to ostavljam za vježbu.
Pogledajmo kako izgleda postupak učenja kroz epohe, točnije kako izgleda broj pogrešnih klasifikacija kroz epohe: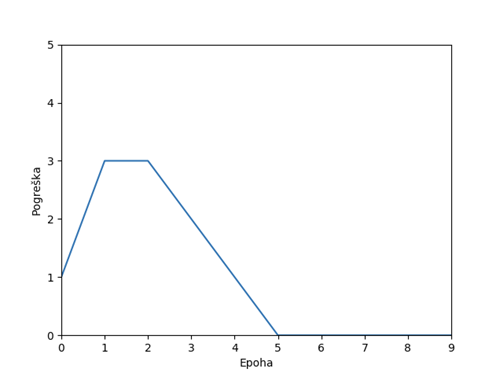 Kao što vidimo iz priloženog, perceptron je naučio klasificirati u šestoj epohi (indeksiranje epoha kreće od 0). Po teoriji, ovdje bi se učenje trebalo prekinuti, no kao što je već rečeno, mi odrađujemo 10 epoha učenja.
Kao što vidimo iz priloženog, perceptron je naučio klasificirati u šestoj epohi (indeksiranje epoha kreće od 0). Po teoriji, ovdje bi se učenje trebalo prekinuti, no kao što je već rečeno, mi odrađujemo 10 epoha učenja.
Pogledajmo kako izgleda granica između klasa za ovaj naš perceptron:
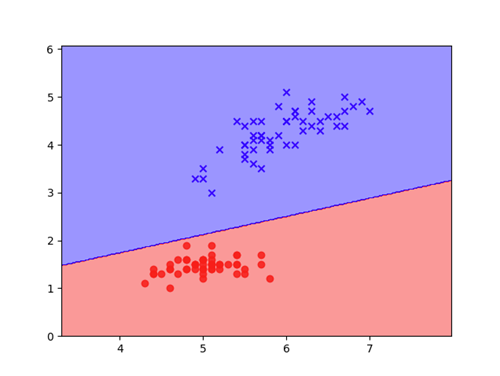 Vidimo da je naš perceptron pronašao jedan od beskonačno mogućih pravaca koji odvajaju ove primjere jedne od drugih. Sada će svaki novi primjer kojeg predamo perceptronu na previđanje pasti u jedno od ova dva područja te će tako biti i klasificiran.
Vidimo da je naš perceptron pronašao jedan od beskonačno mogućih pravaca koji odvajaju ove primjere jedne od drugih. Sada će svaki novi primjer kojeg predamo perceptronu na previđanje pasti u jedno od ova dva područja te će tako biti i klasificiran.
I to je zapravo to! Napisali smo i naučili naš jednostavni model perceptrona. Mogli bismo reći i našu prvu neuronsku "mrežu". Naime, ovdje je riječ o samo jednom neuronu, tako da ovo i nije mreža, ali perceptron je kao model dovoljno jednostavan da se shvate temelji i osnova "pravih" (dubokih) neuronskih mreža. "Prave" se neuronske mreže od našeg perceptrona razlikuju po tome što koriste druge prijenose funkcije (sigmoidu, tangens hiperbolni ili u današnje vrijeme zglobnicu ili ispravljačku linearnu jedinicu, tj. ReLU), imaju više neurona po sloju i imaju više slojeva. Naš perceptron zapravo ima samo jedan sloj i jedan neuron u tom sloju. Naravno, ono najvažnije što razlikuje (duboke) neuronske mreže od našeg perceptrona je sam algoritam učenja (traženja i podešavanja težina). Riječ je o algoritmu koji je sve promijenio i koji je omogućio razvoj neuronskih mreža - algoritam propagacije unatrag. No o njemu i o "pravim" neuronskim mrežama nekom drugom prilikom, ako je uopće i bude jer je taj algoritam temeljen na malo tvrđoj matematici i vrlo ga je teško, ako ne i nemoguće objasniti bez te matematike.
Čitavi kod našeg perceptrona:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# perceptron.py
#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotregije as pr
class Perceptron(object):
def __init__(self, eta=0.01, epochs=10):
self.eta = eta
self.epochs = epochs
def fit(self, X, y):
self.weights = np.zeros(1 + X.shape[1])
self.errors = []
for _ in range(self.epochs):
misclassifications = 0
for x, t in zip(X, y):
correction = self.eta * (t - self.predict(x))
self.weights[1:] += correction * x
self.weights[0] += correction
misclassifications += int(correction != 0.0)
self.errors.append(misclassifications)
return self.errors
def predict(self, X):
return np.where(self._net(X) > 0.0, 1, 0)
def _net(self, X):
# ovo je "privatna" metoda što podvlaka _ prije naziva i označava
return np.dot(X, self.weights[1:]) + self.weights[0]
if __name__ == '__main__':
# dohvat i priprema podataka
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', 0, 1)
X = df.iloc[0:100, [0, 2]].values
p = Perceptron()
errors = p.fit(X, y)
prediction = p.predict([3.5, 4])
print(prediction)
S ovim smo završili još jedan vodič kroz umjetnu inteligenciju i obradili još jedan od alata, tj. algoritama vezanih uz umjetnu inteligenciju. Zapravo, samo smo načeli, tek zagrizli komadić najmoćnije tehnologije umjetne inteligencije današnjice - umjetnih (dubokih) neuronskih mreža.
Isprobajte primjer kod sebe, probajte se igrati. Probajte algoritam napisati vektorski, bez petlje. Kao i uvijek, komentirajte, diskutirajte, pitajte!
P.S. Ovaj je vodič nastao (barem 85% njega) još prije par godina. Međutim nikako da nađem vremena (i volje, prije nego vremena) da ga završim i konačno objavim. U to vrijeme (znači, prije 2-3 godine) duboke su neuronske mreže tek dobivale maha na nekoj poštenoj razini. Sve što je tu napisano aktualno je i danas, ali da je tada objavljeno, bilo bi možda i aktualnije. Barem kao literatura jer u ono vrijeme nije bilo previše objašnjenja na ovakvoj nekoj osnovnoj razini. I tako, zbog konferencije .debug i kasnije Bugovog tuluma na kojem sam obećal Miri da ću objaviti nastavak na genetske algoritme, točno četiri godine kasnije stiže i ova tema.
Pitonce... Svaka cast na trudu. Nesto konacno konkretno i ovdje na forumu. Nedostaje ti "pedagogija". Vrlo brzo si krivulju od pocetnika odveo daleko i nazvao to "naceli smo" .
Imas i nekih greskica tipa - pogledajmo sljedecu slku, a nakon toga ide tekst iz ove slike - ali slike nema. Vuce poprilicno na copy paste. Mene osobno "machine learning" jako zanima pa samo nastavi 
EDIT : Ha, da nakon editiranja nema vise tog teksta bez slike.
P.S. Nego buduci da si u tome. Jel' python uopce ima buducnosti u tome ? Koliko sam ja citao on je po tom pitanju kao onomad basic u programiranju.
1domagoj1
uto 24.12.2019 01:43
SamoPitam3 kaže...
Pitonce... Svaka cast na trudu. Nesto konacno konkretno i ovdje na forumu. Nedostaje ti "pedagogija". Vrlo brzo si krivulju od pocetnika odveo daleko i nazvao to "naceli smo" .
Imas i nekih greskica tipa - pogledajmo sljedecu slku, a nakon toga ide tekst iz ove slike - ali slike nema. Vuce poprilicno na copy paste. Mene osobno "machine learning" jako zanima pa samo nastavi
Mislim da sam poispravljao sve, dugo me nije bilo na forumu, već zaboravih koliko je ovo uređivanje teksta ćudljivo.
Da, sve je kopirano jer je unaprijed pripremljeno.
 Što se tiče krivulje, možda. Ali stvarno je teško moguće jednostavnije od ovoga, žal mi je. Krenul sam malo od osnovnih pojmova i koncepata (općenitih), onda kratko o perceptronu i konačno implementacija. I da, stvarno smo tek načeli...
Što se tiče krivulje, možda. Ali stvarno je teško moguće jednostavnije od ovoga, žal mi je. Krenul sam malo od osnovnih pojmova i koncepata (općenitih), onda kratko o perceptronu i konačno implementacija. I da, stvarno smo tek načeli... 
1domagoj1
uto 24.12.2019 01:47
SamoPitam3 kaže...
P.S. Nego buduci da si u tome. Jel' python uopce ima buducnosti u tome ? Koliko sam ja citao on je po tom pitanju kao onomad basic u programiranju.
Python je doslovno carski jezik što se tiče njegovog korištenja u strojnom i dubokom učenju. Tu je još i R, ali u puno manjoj mjeri. Python vlada. Bez njega gotovo pa možeš sjest i plakat.
1domagoj1 kaže...
SamoPitam3 kaže...
P.S. Nego buduci da si u tome. Jel' python uopce ima buducnosti u tome ? Koliko sam ja citao on je po tom pitanju kao onomad basic u programiranju.
Python je doslovno carski jezik što se tiče njegovog korištenja u strojnom i dubokom učenju. Tu je još i R, ali u puno manjoj mjeri. Python vlada. Bez njega gotovo pa možeš sjest i plakat.
Mislim da smo se slabo razumjeli. I basic je bio dobar kada je, well, bio dobar. Cisto me zanima ono dalje. Znam ja da je python najbolji trenutno po tom pitanju (ali i js moze (po)sluziti tome kada smo kod toga, da ne spominjem javu koje je danas iznad R), ali zanima me ono dalje. Ima li najava novih "jezika" koji ce to odvesti na visu razinu.
 malak
uto 24.12.2019 08:06
malak
uto 24.12.2019 08:06
Odličan tutorial, svaka čast. Jedno pitanje, imas li preporučiti kakvu literaturu u moru današnjih informacija, što loših a što dobrih ?
1domagoj1
uto 24.12.2019 11:58
SamoPitam3 kaže...
Mislim da smo se slabo razumjeli. I basic je bio dobar kada je, well, bio dobar. Cisto me zanima ono dalje. Znam ja da je python najbolji trenutno po tom pitanju (ali i js moze (po)sluziti tome kada smo kod toga, da ne spominjem javu koje je danas iznad R), ali zanima me ono dalje. Ima li najava novih "jezika" koji ce to odvesti na visu razinu.
Aha. Pa mislim, BASIC je i dalje dobar, za to za što je dobar. xD
Uglavnom, smatram da ne. Trenutno je Python najrasprostranjeniji i mislim da ne bude još dugo otišel, s obzirom da postoji hrpetina biblioteka (optimiranih i zrelih) pisanih upravo za Python. Jedna takva je i biblioteka NumPy koju sam koristil gore u tutorijalu. Zatim je tu što se strojnog učenja tiče biblioteka sklearn (sa svim svojim statističkim čudesima). Tu su biblioteke za rukovanje podacima poput spomenutog pandasa. Što se tiče dubokog učenja, dvije najrasprostranjenije biblioteke su PyTorch i Tensorflow, obje napisane za Python (imaju i implementacije u C++-u te ostalim jezicima, ali ne toliko potpune kao implementacije u Pythonu).
Ono što vidim da bi se možda moglo dogoditi je da JavaScript postane vrlo korišten jezik jer svjedočimo tome da je od skriptnog jezika za pretraživače postal sveprisutni jezik (počevši s node.js-om). Uz to, ima hrpu novotarija u standardu ES6 i ES7 čime postaje neloš jezik. Međutim, ništa od toga nije toliko bitno jer su svi ti jezici iste imperativne paradigme. Razlika je samo u veličini zajednice i podrški u vidu popratnih biblioteka i alata. A Python tu trenutno prednjači.
Nadalje, tu su i neki novi programski jezici koji su se pojavili kao rivali Pythonu, kao npr. Julia, koja iako je jezik opće namjene, ima određene ugrađene značajke zbog kojih je prikladan jezik za numeričku analizu. No nedostaje joj zaleđa koje ima Python. Java, C#, pa i C++ su tu da bi ubrzali stvari, nipošto da bi se u njima razvijalo. Naime, razviješ model u Pythonu i PyTorchu/Tensorflowu, naučiš ga (što znači, kao što je rečenu u tutorijalu, naći odgovarajuće težine) i onda taj model (tj. skup svih tih težina) upucaš u implementaciju napisanu u nekom bržem jeziku. To je nešto što se redovito radi.
Što se tiče konkretnog "dalje" nakon dubokog učenja, ne znam. Veliki problem dubokog učenja je u tome što je to zapravo plitko područje nauke. Izraz "duboko" se odnosi na arhitekturu mreže: svaka mreža koja ima od nekoliko skrivenih slojeva pa do par stotina ili više naziva se dubokom. Zato je tu ime duboko učenje. No što se tiče teoretske podloge i zaleđa, gotovo pa nema ničega. Postoji teorem o univerzalnoj aproksimaciji (teorem Cybenka, Cybenkov teorem) i to je praktički to. Sve drugo je nabadanje i empirijsko nagađanje. Nema garancije konvergencije modela, nema garancije performansi bilo kakve vrste (kao u srodnim područjima strojnog učenja, tipa jezgrine metode, rijetki linearni modeli i sl.). Vladimir Naumovič Vapnjik koji je zajedno s Aleksejеm Jakovljevičem Červonjenkisom osmislil Vapnjik-Červonjenkisovu teoriju koja se smatra "temeljnom teorijom učenja" (objašnjava proces učenja sa statističkog stajališta) jednom je izjavio: "Najpraktičnija stvar na svijetu, dobra je teorija.". To je ono što mi nemamo. Modeli su gladni za previše označenih podataka, treba im predugo i previše resursa da se nauče, a često i podbace kod učenja. Hiperparametri (točnije, broj slojeva, broj neurona po sloju) su i dalje misterija, crna kutija. Oko toga nema nikakve automatizacije niti ikakvih procjena ili pravila - sve se svodi na intuiciju podatkovnog znanstvenika ili inženjera. Sve su to problemi jer nemamo nikakve čvrste teorije.
Tako da, što se tiče toga "dalje", zapravo to ne ovisi o nikakvim programskim jezicima, oni su tu sporedni, samo su alat koji koristimo. To "dalje" ovisi o teorijskoj podlozi i matematici te podloge.
Nadam se da sam sad uspel odgovoriti na pitanje, barem koliko-toliko. :)
malak kaže...
Odličan tutorial, svaka čast. Jedno pitanje, imas li preporučiti kakvu literaturu u moru današnjih informacija, što loših a što dobrih ?
Naravno, pošaljem PP.
 Mitch
sub 28.12.2019 23:45
Mitch
sub 28.12.2019 23:45
1domagoj1 kaže...
SamoPitam3 kaže...
P.S. Nego buduci da si u tome. Jel' python uopce ima buducnosti u tome ? Koliko sam ja citao on je po tom pitanju kao onomad basic u programiranju.
Python je doslovno carski jezik što se tiče njegovog korištenja u strojnom i dubokom učenju. Tu je još i R, ali u puno manjoj mjeri. Python vlada. Bez njega gotovo pa možeš sjest i plakat.
Ha mislim, dok je Anaconda tu ne vidim zasto bi ljudi uopce trazili nesto drugo. Plug and play i jednostavna sintaksa 
 kexzoR
čet 2.1.2020 18:07
kexzoR
čet 2.1.2020 18:07
1domagoj1 kaže...
SamoPitam3 kaže...
Mislim da smo se slabo razumjeli. I basic je bio dobar kada je, well, bio dobar. Cisto me zanima ono dalje. Znam ja da je python najbolji trenutno po tom pitanju (ali i js moze (po)sluziti tome kada smo kod toga, da ne spominjem javu koje je danas iznad R), ali zanima me ono dalje. Ima li najava novih "jezika" koji ce to odvesti na visu razinu.
Aha. Pa mislim, BASIC je i dalje dobar, za to za što je dobar. xD
Uglavnom, smatram da ne. Trenutno je Python najrasprostranjeniji i mislim da ne bude još dugo otišel, s obzirom da postoji hrpetina biblioteka (optimiranih i zrelih) pisanih upravo za Python. Jedna takva je i biblioteka NumPy koju sam koristil gore u tutorijalu. Zatim je tu što se strojnog učenja tiče biblioteka sklearn (sa svim svojim statističkim čudesima). Tu su biblioteke za rukovanje podacima poput spomenutog pandasa. Što se tiče dubokog učenja, dvije najrasprostranjenije biblioteke su PyTorch i Tensorflow, obje napisane za Python (imaju i implementacije u C++-u te ostalim jezicima, ali ne toliko potpune kao implementacije u Pythonu).
Ono što vidim da bi se možda moglo dogoditi je da JavaScript postane vrlo korišten jezik jer svjedočimo tome da je od skriptnog jezika za pretraživače postal sveprisutni jezik (počevši s node.js-om). Uz to, ima hrpu novotarija u standardu ES6 i ES7 čime postaje neloš jezik. Međutim, ništa od toga nije toliko bitno jer su svi ti jezici iste imperativne paradigme. Razlika je samo u veličini zajednice i podrški u vidu popratnih biblioteka i alata. A Python tu trenutno prednjači.
Nadalje, tu su i neki novi programski jezici koji su se pojavili kao rivali Pythonu, kao npr. Julia, koja iako je jezik opće namjene, ima određene ugrađene značajke zbog kojih je prikladan jezik za numeričku analizu. No nedostaje joj zaleđa koje ima Python. Java, C#, pa i C++ su tu da bi ubrzali stvari, nipošto da bi se u njima razvijalo. Naime, razviješ model u Pythonu i PyTorchu/Tensorflowu, naučiš ga (što znači, kao što je rečenu u tutorijalu, naći odgovarajuće težine) i onda taj model (tj. skup svih tih težina) upucaš u implementaciju napisanu u nekom bržem jeziku. To je nešto što se redovito radi.
Što se tiče konkretnog "dalje" nakon dubokog učenja, ne znam. Veliki problem dubokog učenja je u tome što je to zapravo plitko područje nauke. Izraz "duboko" se odnosi na arhitekturu mreže: svaka mreža koja ima od nekoliko skrivenih slojeva pa do par stotina ili više naziva se dubokom. Zato je tu ime duboko učenje. No što se tiče teoretske podloge i zaleđa, gotovo pa nema ničega. Postoji teorem o univerzalnoj aproksimaciji (teorem Cybenka, Cybenkov teorem) i to je praktički to. Sve drugo je nabadanje i empirijsko nagađanje. Nema garancije konvergencije modela, nema garancije performansi bilo kakve vrste (kao u srodnim područjima strojnog učenja, tipa jezgrine metode, rijetki linearni modeli i sl.). Vladimir Naumovič Vapnjik koji je zajedno s Aleksejеm Jakovljevičem Červonjenkisom osmislil Vapnjik-Červonjenkisovu teoriju koja se smatra "temeljnom teorijom učenja" (objašnjava proces učenja sa statističkog stajališta) jednom je izjavio: "Najpraktičnija stvar na svijetu, dobra je teorija.". To je ono što mi nemamo. Modeli su gladni za previše označenih podataka, treba im predugo i previše resursa da se nauče, a često i podbace kod učenja. Hiperparametri (točnije, broj slojeva, broj neurona po sloju) su i dalje misterija, crna kutija. Oko toga nema nikakve automatizacije niti ikakvih procjena ili pravila - sve se svodi na intuiciju podatkovnog znanstvenika ili inženjera. Sve su to problemi jer nemamo nikakve čvrste teorije.
Tako da, što se tiče toga "dalje", zapravo to ne ovisi o nikakvim programskim jezicima, oni su tu sporedni, samo su alat koji koristimo. To "dalje" ovisi o teorijskoj podlozi i matematici te podloge.
Nadam se da sam sad uspel odgovoriti na pitanje, barem koliko-toliko. :)
malak kaže...
Odličan tutorial, svaka čast. Jedno pitanje, imas li preporučiti kakvu literaturu u moru današnjih informacija, što loših a što dobrih ?
Naravno, pošaljem PP.
Moze i meni literatura? Unaprijed hvala!
Hvala puno na tutorialu! Mogu li te i ja zamoliti za literaturu?
Pozdrav svima, nakon dugo vremena (točno 4 godine) evo nas u novom vodiču kroz umjetnu inteligenciju! Ovoga puta obrađujemo umjetne neuronske mreže (bar nekakvi početak). Svi znamo kako se u posljednje vrijeme mnogo spominje umjetna inteligencija koja je sve bolja i bolja u zadacima koji su donedavno bili rezervirani samo za čovjeka jer je bilo nemoguće razviti eksplicitni algoritam koji bi mogao obraditi te zadatke. Neki primjeri takvih zadataka su: raspoznavanje objekata na slikama (računalni vid), strojno prevođenje teksta, automatska analiza teksta (npr. izvlačenje sentimenta iz komentara, generiranje sažetka iz velikog komada teksta i sl.) ili razumijevanje govora. U svakom od navedenih primjera dimenzionalnost podataka je iznimno velika i zapravo je nemoguće osmisliti nekakav eksplicitni algoritam koji bi radio bilo što od navedenog samo na temelju nekakvih pravila.
Stoga, da bi riješili ovaj problem, okrećemo se jednom drugačijem pristupu. Umjesto da kodiramo eksplicitan algoritam, mi ćemo osmisliti algoritam koji će imati sposobnost iz gomile podataka sam naučiti tzv. hipotezu. Struktura tih podataka može biti jako kompleksna, no to nas ne brine jer teret učenja hipoteze prebacujemo na sam algoritam. Takav postupak gdje imamo podatke na temelju kojih se algoritam uči naziva se nadzirano učenje.
Postupcima nadziranog učenja mogu se rješavati dvije vrste problema: klasifikacija i regresija. Kod klasifikacije određujemo kojoj klasi (razredu) pripada neki novi primjer podatka koji smo dobili, a kod regresije primjeru pridružujemo neku kontinuiranu vrijednost (npr. aproksimacija funkcije). Razlika je dakle u tome je li ciljana varijabla diskretna (klasifikacija) ili je kontinuirana (regresija).
U prošlom tutorijalu (na ovoj poveznici) bavili smo se jednom drugom granom umjetne inteligencije - genetskim algoritmima i tamo smo rješavali problem regresije (aproksimirali smo funkciju). U ovom tutorijalu/vodiču bavit ćemo se granom umjetne inteligencije koja je danas iznimno vruća i aktivna - dubokim učenjem (točnije nekom osnovom svega). Pokušat ću čim jednostavnije opisati što su to neuronske mreže, kako rade i kako ih se uči. Genetski algoritmi koje smo obrađivali prošli put inspirirani su evolucijom, jednostavni za shvatiti i bez matematike. Neuronske mreže također su inspirirane prirodom tj. mozgom i načinom na koji on radi, možda su mrvicu kompleksnije za shvatiti kako rade, ali za rigorozno objašnjenje rada imaju matematike i to dosta teške matematike koju ću pokušati svesti na minimum.
Kao što sam već spomenuo, prošlog smo se puta bavili problemom regresije, a sada ćemo se baviti problemom klasifikacije. Ukratko, radi se o tome da imamo označene podatke gdje svaki podatak ima pridruženu klasu. Na temelju tih podataka učimo neuronsku mrežu. Zatim dobijemo novi, ovaj puta neoznačeni podatak i ubacimo ga u neuronsku mrežu. Njezin je zadatak tom neoznačenom podatku dodijeliti neku klasu za koju mreža smatra da joj taj podatak pripada. Dakle, zadaća je klasifikacijskog algoritma (u ovom slučaju neuronske mreže) naučiti hipotezu h: X -> {0, 1} koja određuje pripada li neki primjer x klasi C ili ne:
Primjetimo da je ovdje riječ o K međusobno *isključivih* stanja, dakle podatak u ovom slučaju može pripadati isključivo *jednoj* klasi. Ovakav slučaj ne mora biti i u praksi: npr. novinski članak može pripadati u dvije ili tri rubrike po svom sadržaju, tj. u više klasa. To je općeniti slučaj i naziva se klasifikacija s višestrukim oznakama (engl. multilabel classification) ili klasifikacija tipa jedan-na-više. Međutim, takav slučaj nije potrebno posebno razmatrati budući da se može izvesti kao klasifikacija tipa jedan-na-jedan koju smo do sada opisali.
Sada kada smo pokrili neku osnovnu terminologiju, možemo krenuti sa samim neuronskim mrežama. Kao što sam već rekao, neuronske su mreže inspirirane mozgom. Razvoj neuroračunarstva i umjetnih neuronskih mreža započeo je 40-tih godina prošlog stoljeća potaknut nizom bioloških spoznaja. Još 1943. godine McCulloh i Pitts su u svom radu predstavili prvi koncept pojednostavljenog umjetnog neurona i pokazali da se njime mogu računati logičke funkcije I, ILI i NE. Međutim, važno je napomenuti da se ovdje radilo o rješavanju problema konstrukcijom, a ne učenjem. Oni su zapravo izgradili (ručno konstruirali) umjetnu neuronsku mrežu na način da dobiju proizvoljnu Booleovu funkciju. Kasnije, 1949. godine britanski biolog Donald Hebb u svojoj knjizi objavljuje spoznaje o radu bioloških neurona. On je zapazio da ako dva neurona često zajedno pale, tada dolazi do metaboličkih promjena kojima efikasnost kojom jedan neuron pobuđuje drugoga s vremenom raste. Drugim riječima, njegova je ideja da učiti znači mijenjati jakost veza između neurona. Na temelju te ideje osmišljen je prvi algoritam učenja McCullohove i Pittsove mreže (tzv. TLU-perceptrona) kojeg je osmislio Frank Rosenblatt 1962. godine i to je algoritam s kojim ćemo prvo krenuti i kojeg ćemo prvo implementirati. Kao što možete primjetiti, ideja umjetnih neuronskih mreža seže daleko u prošlost, ali tek 2010-ih godina (koja godina prije) postaju konkretno upotrebljive. Razlog tome je razvoj Interneta i posljedično dostupnost abnormalnih količina podataka (pogotovo društvene mreže i sve ostale "besplatne" usluge koje zapravo nisu besplatne jer poklanjamo svoje privatne podatke) te razvoj računalnog sklopovlja, naročito paralelnog sklopovlja kao što je npr. tehnologija CUDA ili tehnologija OpenCL.
Kao i u prošlom tutorijalu i u ovom ćemo za implementaciju koristiti programski jezik Python. Jedan od razloga je dakako to što je Python vrlo jednostavan i čitljiv jezik kojeg lako mogu razumijeti i oni koji ga ne znaju (vrlo je sličan pseudokodu). Svu sintaksu koja je specifična za Python dodatno ću pojasniti. Drugi razlog je taj što je Python kao jezik izrazito popularan u znanstvenoj zajednici, pa tako i u području računarske znanosti i za njega postoji mnogo biblioteka koje se koriste za kojekakve proračune kao npr. biblioteka za "drobljenje" brojeva NumPy koju ćemo koristiti i mi.
Dodatne biblioteke koje ćemo koristiti su već spomenuti NumPy za numeričke proračune, matplotlib za iscrtavanje rezultata te biblioteka pandas za rad s podatkovnim strukturama. Operacijski sustav na kojem je sve napravljeno je Linux Ubuntu 16.04 jer i inače na tom sustavu programiram/radim/igram, a i instalirati sve potrebne alate na Linuxu je prejednostavno. Python je već instaliran, a za instalirati numpy, matplotlib i pandas dovoljno je u naredbenom retku ukucati (ako više volite grafički način, potražite te pakete u Synapticu):
sudo apt install python3-numpy python3-matplotlib python3-pandas
ili ako preferirate PyPI:
pip3 install numpy
pip3 install matplotlib
pip3 install pandas
NAPOMENA: imajte na umu, kao što se može i vidjeti iz ovih naredbi za instalaciju, da je inačica Pythona koja se koristi 3, a ne 2. Dakle, koristimo Python 3, a ne Python 2 koji, ako se ne varam, i dalje dolazi kao zadana instalacija u praktički svim distribucijama Linuxa. Tako da ukoliko nemate instaliran Python 3, instalirajte ga jednostavnim:
sudo apt install python3.5 # ili noviji od 3.5 ako postoji u repozitorijima
Sada kada su svi potrebni alati instalirani, možemo krenuti s implementacijom našeg prvog jednostavnog umjetnog neurona - TLU-perceptrona (od engl. threshold logic unit). Da bismo mogli implementirati naš umjetni neuron, moramo se zapitati kako izgleda biološki neuron.
Ukupnu pobudu net računamo prema izrazu:
Ostao nam je još jedan, najbitniji dio, a to je sam proces učenja. Učenje kod neuronskih mreža svodi se na podešavanje težina w0 do wn (sjetimo se Hebbove ideje od ranije da učiti znači mijenjati jakost veza) na takav način da se neuroni pobuđuju (pale) kad nam to treba, a isto tako i da ostaju neaktivni kad nam treba neaktivnost. Za perceptron je osmišljeno sljedeće pravilo:
- ukoliko se primjer klasificira ispravno tada nemoj raditi nikakvu korekciju težina
- ukoliko se primjer klasificira neispravno tada primjeni korekciju na težine
- ciklički uzimaj sve primjere redom, a postupak zaustavi kada su svi primjeri klasificirani ispravno
Korekcija težina vrši se na sljedeći način: